This month, I finished the final series of hyperparameter tuning and optimization on the Kaggle Titanic Random Forest Model. I constructed this model for the Kaggle Machine Learning from Disaster challenge, which is an introductory-level machine learning prediction competition. Users are supposed to construct a model that predicts whether or not a given person, among 800 people, survived the Titanic shipwreck. This was my first attempt at crafting a new AI model from (close to) scratch, given a fully-featured dataset. Although I probably could achieve higher Kaggle scores by trying out different architectures, I didn’t want to spend the entire year on one challenge, and left the model at a 0.788 public score.
In this post, I explore some of the code and the inner workings behind the Kaggle Random Forest model. I also dive into a few of the challenges I encountered along the way. If you’d like to work off the model framework I’ve put on GitHub, you can feel free to do that, but I’d strongly recommend against it because I haven’t yet taken the time to make the code fully understandable and customizable. (Also, a serious Kaggle competitor will likely strive for a better model architecture that achieves a higher public score, so please find your own setup).
Model Setup: From Logistic Regression to Random Forest
Initially, I started off with a simple logistic regression model loosely based on a Kaggle starter tutorial. For the most part, the tutorial model didn’t involve any careful feature engineering, and primarily relied on the passenger name, class, sex, age, and fare (several of the most important features in the dataset). It used elementary techniques to learn patterns between these features and the survival, and this base model only achieved an accuracy of about 0.74 inside the code cell.
Immediately realizing that I needed to do more with the model, I switched to a Random Forest architecture, as it seemed to be highly recommended for binary classification problems like this one. The important part about Random Forest is that the model automatically determines which features are the most important, regressing through all the available features in a large “tree”. So I was able to feed it a wide variety of featuers and have it discover the most important connections: the prominent features ended up being Sex, Pclass, and Fare/Age.
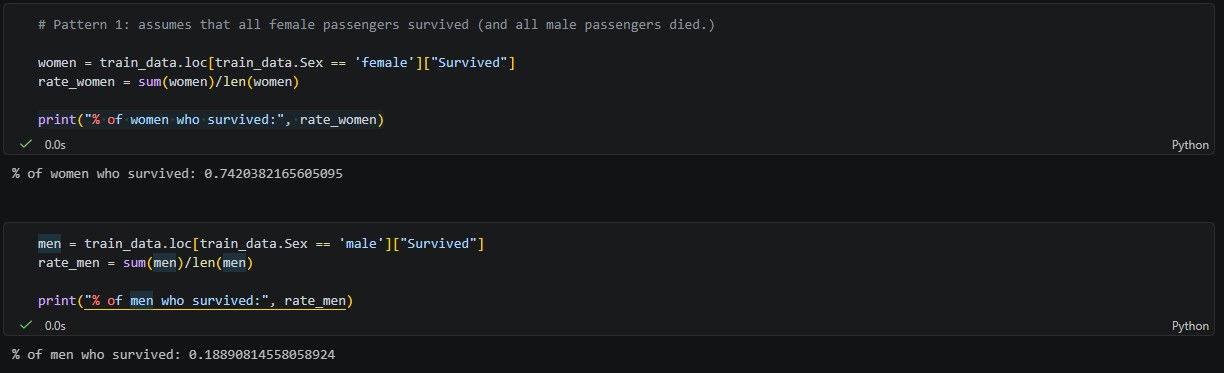
As shown in the image above, I was able to discover that a significantly higher percentage of women survived than men (74% vs 18%). Historically, this was due to the “women and children first” directive on the ship. I used this basic pattern to train the original model, and the more advanced Random Forest model uncovered this connection as well. I prioritized the Sex feature (in addition to Pclass and Fare/Age) when feeding the features to the model.
Advanced Feature Engineering: the Cabin Data
When the Random Forest model based only on Sex, Pclass, and Fare/Age didn’t perform very well, I realized I was going to have to do a lot more feature engineering. After all, the data contains several features, ranging from the number of parents and children aboard the Titanic, to the passenger’s Ticket number, and the cabin number where the passenger stayed.
Since the location of the passenger aboard the vessel seemed like an important data point, I constructed the next round of feature engineering around the Cabin column (and created a few new helpful features from the existing data, like IsAlone or FamilySize). I learned quite a bit about proper feature engineering practices in the process; with the help of Copilot and some Google searches, I was able to construct new engineered data for the model to train on.
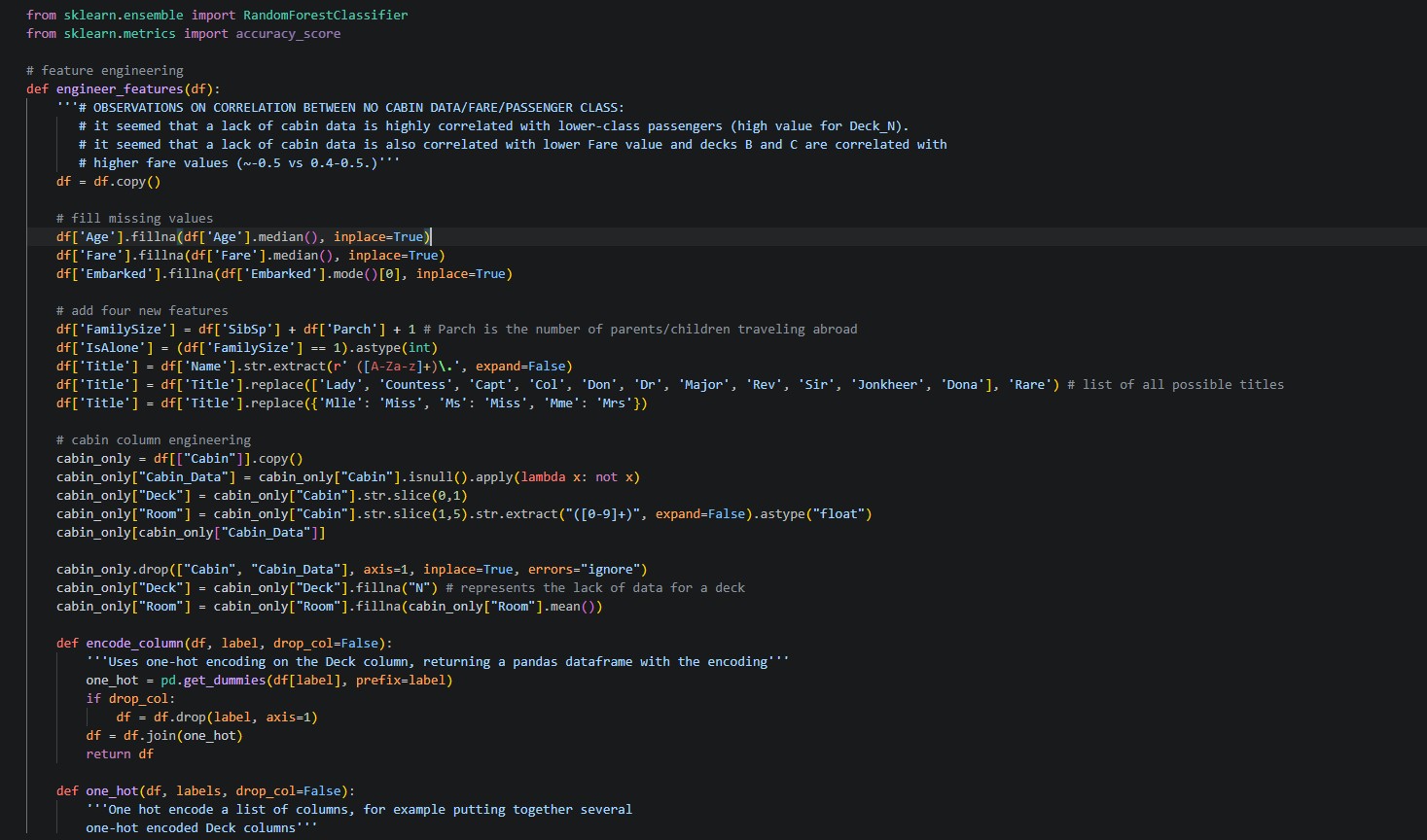
I also built a function to make observations on the correlation between people with no cabin data (we don’t know where they stayed) and passenger class (1st, 2nd, or 3rd class). I wrote these observations at the top of the rather long code cell shown below, and this info actually ended up being helpful in situations where the cabin data was missing.
Hyperparameter Tuning (with RandomizedSearchCV)
After retraining the model with the engineered Cabin data, I was getting much-improved accuracy in the notebook (about 0.82 vs 0.79), but the Kaggle score wasn’t changing. I figured I was going to have to do some more serious hyperparameter tuning to boost the score, which usually only reacts to large-scale prediction changes.
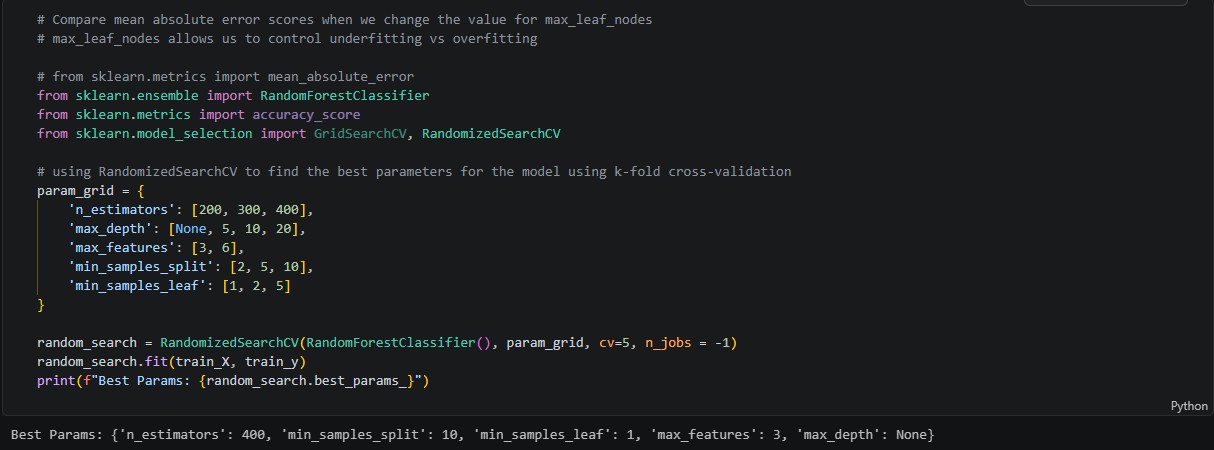
At first, I attempted to tune most of the important parameters (n_estimators, max_depth, max_features) by hand, doing Google searches to figure out the best values for a Random Forest model. But this quickly became tedious, as I had to retrain the model every time I made a minor change so see if it did anything. Instead, I switched to RandomizedSearchCV, which is an algorithmic method of finding a model’s best parameters povided by the Python library sklearn.
Using RandomizedSearchCV was relatively simple (as shown in the code cell below). All I had to do was set up a parameter grid, where I told RandomizedSearchCV which hyperparameters I wanted it to optimize. Then, I asked the algorithm to fit on the training datasets of the model, and then output the best parameters using a simple print() statement. From there, I was able to go back and drop in the fine-tuned parameters to the final model. The parameter-discovery process did take a little while, so I had to set n_jobs = -1 to ensure the algorithm ran on all CPU cores.
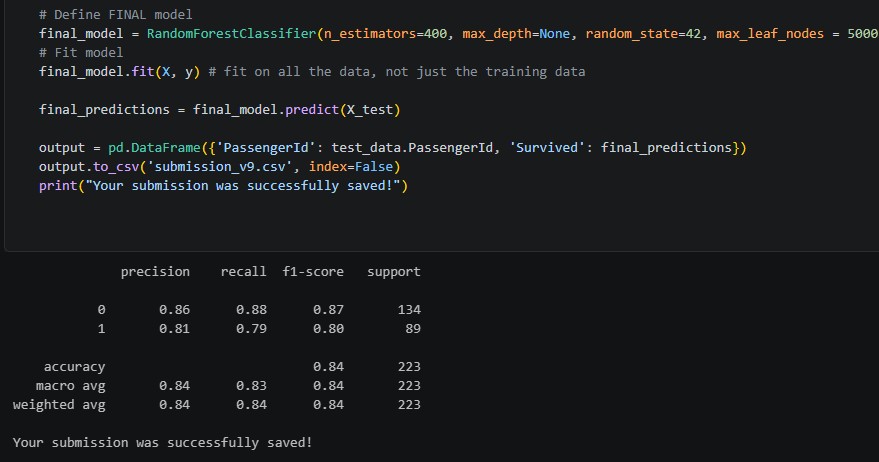
After the hyperparameter tuning, the model achieved 0.84 validation accuracy in the notebook, and a Kaggle public score of 0.788, which is in the mid-to-upper-tier for these kinds of Random Forest models. I haven’t been able to move above this score since then; however, if I manage to do so, I will update this blog post with those details.
To view this entire Titanic project (and the code files) on GitHub, click here. However, the code is primarily intended for reference, not for drop-in usage in a brand-new project.
Leave a Reply