With the academic year classes having come to a conclusion, the summer has officially started. I made a goal for myself back in late April, when things were still extremely busy, that I would try to push harder on the fourth and final book in the Flames of Rebellion series when classes ended. I had just published Book 3.5 on Amazon and was feeling motivated to wrap up the series; Book 4 already had about 9,000 words of content in it from the previews I had written.
Now, as of late May, I’ve mostly achieved that goal. Over the past few days, I’ve put down over 3,000 words into Book 4, The Conquest of Piece, reaching over 12,000 words. Things have gotten significantly more interesting than the first few chapters, and I’m using a rather chaotic mind map with sticky notes to keep track of this book’s plot. In a couple of chapters, the plan is to create a serious plot twist by adding an evacuation situation of the Tranquility’s Ozridia base due to a bomb threat (or possible actual bomb). I’d also like to fully develop and flesh out Jonathan and Lily’s romance, as this is the last book now. I’ve already added some romantic cues in the first few chapters; I intend to make Jonathan’s upcoming birthday party the culmination of their relationship.
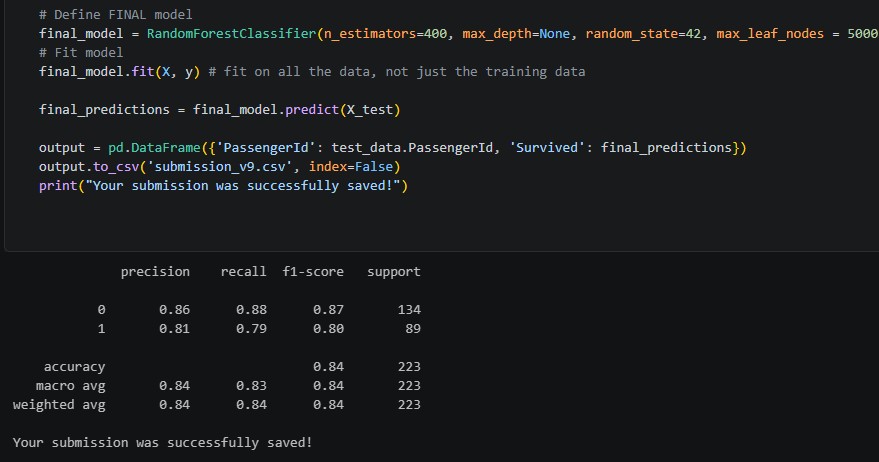
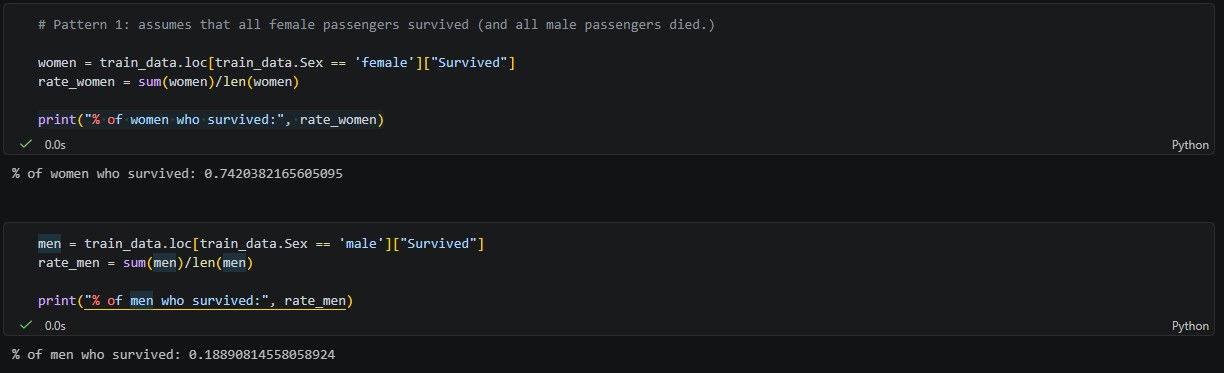
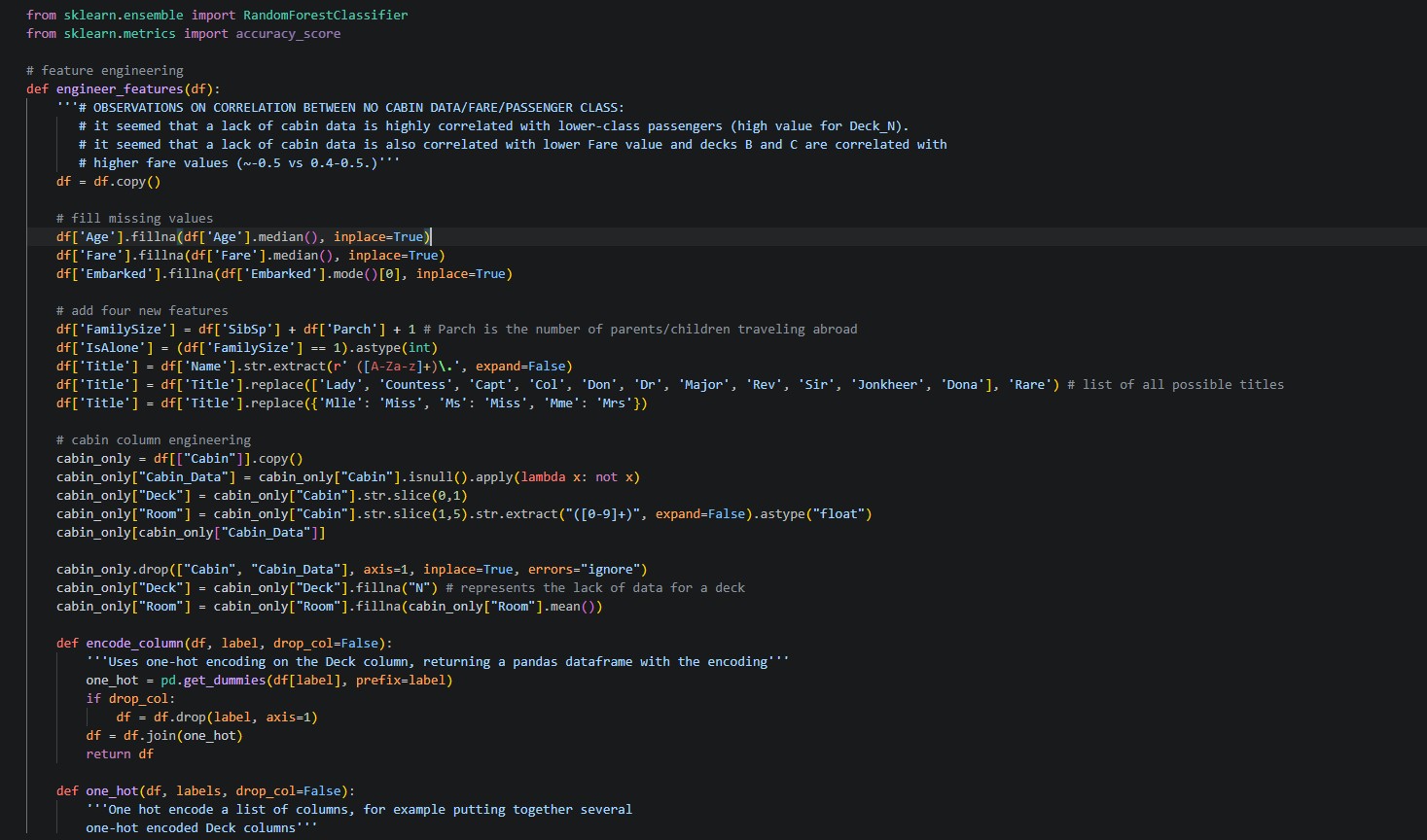
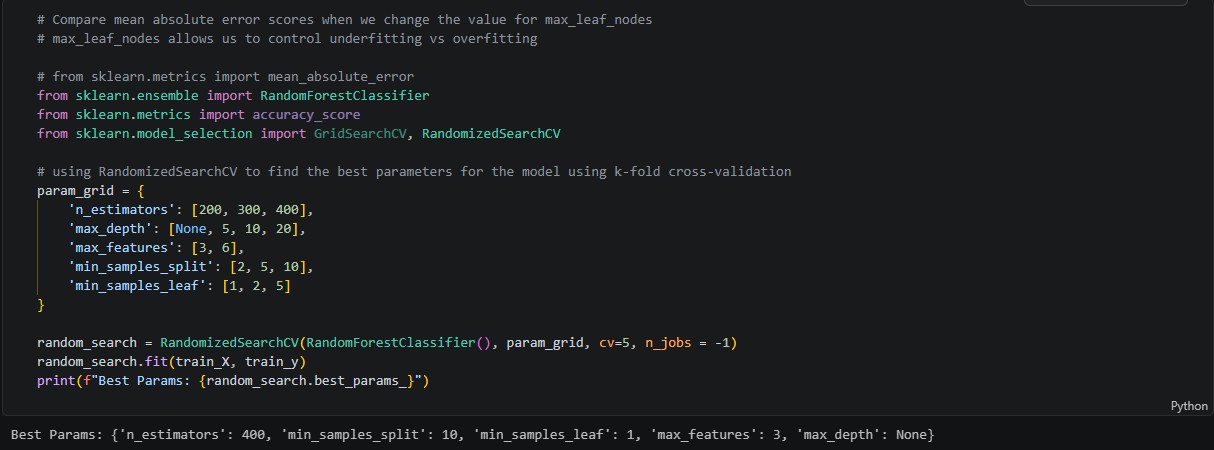
On the subject of artificial intelligence and machine learning, I’ve moved onto a new Kaggle challenge: house price prediction. After failing horribly to get the sentiment analysis model to work, I stopped trying to extract answers from Claude and pivoted to something else. This house price prediction challenge involves the creation of a model to predict the prices of houses in the Iowa area based on various attributes, like number of bedrooms, pool quality, fence presence, square footage, etc. The dataset is quite large; there are seventy-nine features available, all with varying correlations to the central SalePrice target variable. So far, I’ve analyzed the data using some Seaborn scatterplots, generated correlation matrices to see which features to encode, and gotten started on cleaning the data (which has involved deleting outliers and imputing NA values). I can already tell that this challenge, while still labeled “introductory”, is slightly more intensive in terms of data preparation and analysis than the Kaggle Titanic challenge.
I’m also loosely working on the virtual card deck project, where I’m attempting to create a virtual cards app that people can customize to fit their specific needs. Right now, I have a modal where you can input the number of decks, the name of each deck, the background art, and the titles/descriptions for the cards in the deck. Most of the data is persisted, and the modal seems to be behave as expected. However, I’ve been running into trouble getting all the data to save to local Storage, not just the number of decks. I’ve asked lots of questions of Microsoft Copilot, but no real results have come yet. This project is one of the most complex undertakings for me yet when it comes to web design, HTML, and JavaScript, so I’m not expecting it to work perfectly for many more months.
Tomorrow, I’m starting a chamber music perspectives (CMP) camp, which will run for about a week and a half and take place from 1:00 PM to 5:00 PM. This camp involves not only a series of small ensemble performances (piano trio and string quartet size), but also some composition masterclasses and the opportunity to compose a piece of your own for the ensemble to play. This will be the “Final Project”, as it’s been dubbed; it looks like this camp will be very fast-paced and packed with activities. This final project needs to be started from scratch on day one and completed by the tenth day, giving us less than two weeks to compose a fleshed-out, playable, and refined 3-5 minute piece. For context, it usually takes me about two months to compose a high-quality 5-minute multi-instrument piece; however, I only work about 45 minutes every other day. At this camp, we’ll likely spending at least an hour and a half every day on this final project.
Some other miscellaneous endeavors from the past couple of weeks include an AI radio show, which I just finished today. This is the third such show I’ve completed now (well, fourth, if you count Why You Should Be Afraid of Physics Class, a 20-minute-long drama), and I’m using Fish Audio to generate all the voices. These shows generally run for 25-28 minutes, and this latest episode contains the guest host Sal Khan. You’re probably wondering: how did I possibly get Sal Khan to appear on a low-level AI-produced radio show? Because this isn’t an AI-produced show: the voices are all AI. I do the editing and the generating of the voices. Sal Khan is a cloned voice available on Fish Audio, and I’ve cloned a few others for use in these episodes. It’s quite an interesting process, actually. I’ll be using DaVinci Resolve’s Fairlight studio instead of the clunky Audacity to edit this show together. Hopefully it won’t be too much of a shock to use. (The video editor portion of DaVinci Resolve is actually quite easy to learn. I’ve put together quite a few videos with it now).
Well, tomorrow’s going to be quite a busy day, with the starting of the CMP Chamber Music Perspectives camp. I’ll try to work on the AI models this weekend if possible, in addition to the usual (shortened) BeamNG Roleplay sessions. Stay tuned for more updates.