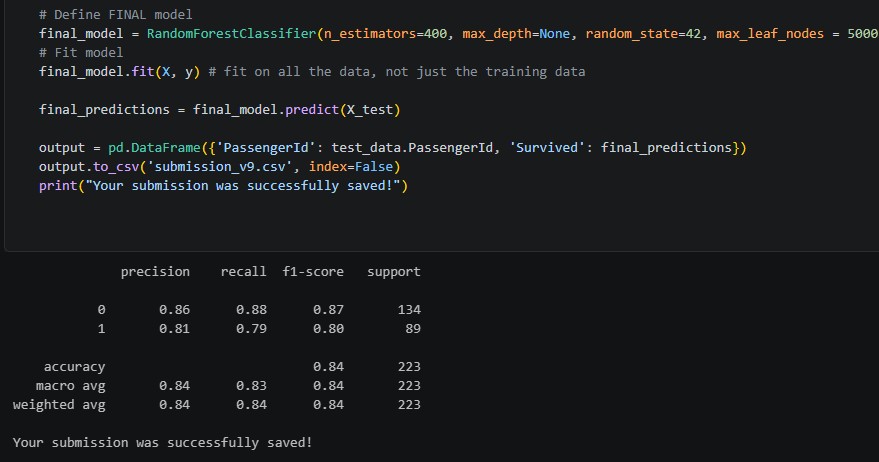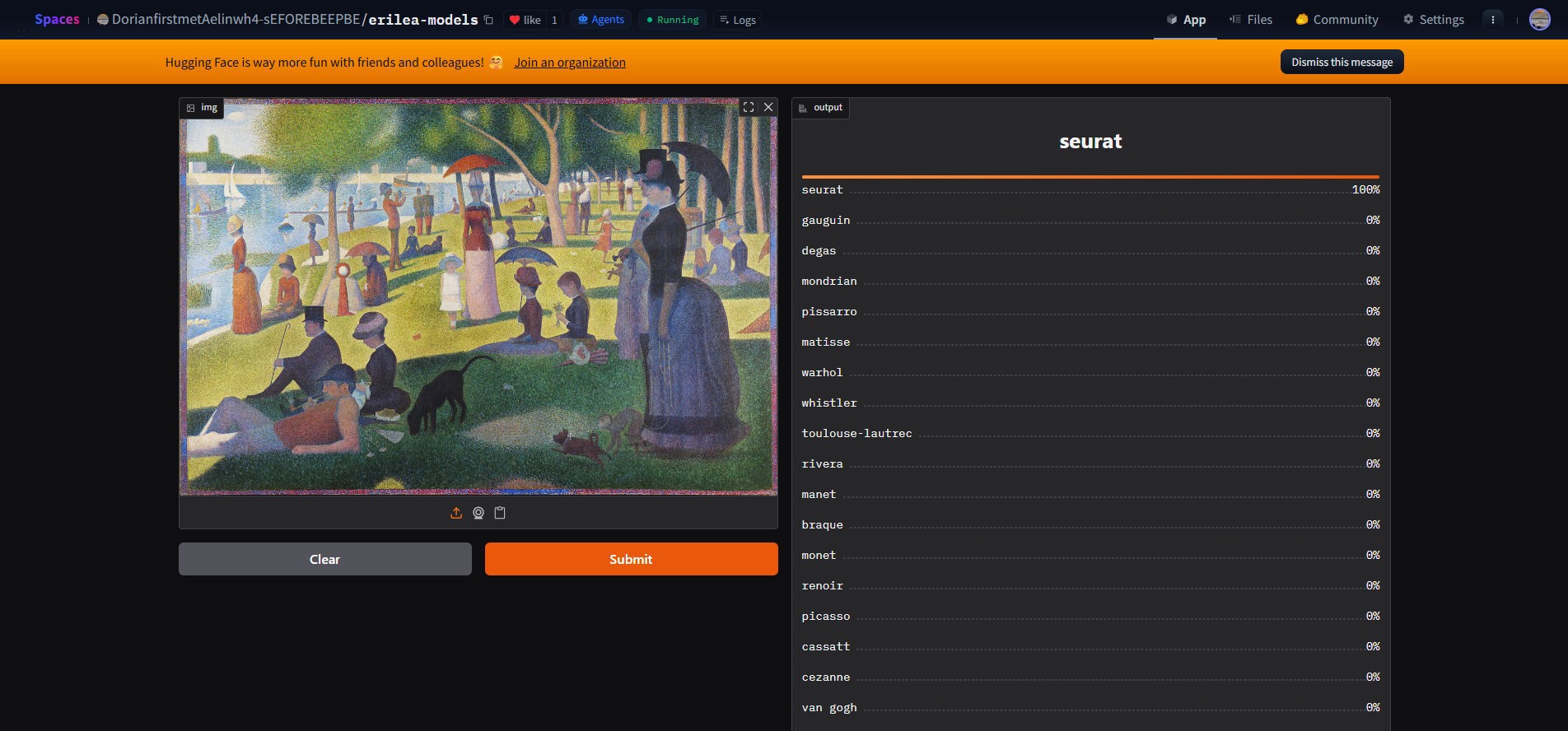
Today, I finally finished setting up the Ashryver V1 Painting Classifier, my latest interactive web-based model, and placed a live embed on the AI, ML, and Web Projects page. You can now interact with the model right from your browser, and upload any painting you choose for the model to make predictions. Although the embed is a little small, and the formatting is still on the uneven side due to WordPress’s lack of flexibility, I hope to have these issues sorted out soon. Besides, my ultimate plan (perhaps once the final, non-prototype Ashryver V2 model comes out) is to place an active HuggingFace API instance of the model on one of my websites. I’ll have to wait until HuggingFace and Gradio sort out a CORS issue first, though, as there have been known issues across all platforms for the past few weeks.
In this post, I’ll provide a brief summary of the training process, the overall model performance, and my future goals now that this project is “finished”.
The Training Process
I started working on the Ashryver V1 model about a week ago. I used the fast.ai foundational framework for this project, moving away from the clunky and cumbersome Tensorflow libraries I had been familiar with before. fast.ai is just an upper layer of Pytorch, which is the latest and most efficient machine learning library. I was blown away by how easy it is to instantly create and train a deep learning model; all it takes is just a few different code cells and some DataBlocks.
As a brief reminder, this Ashryver V1 model is a painting classifier trained on images of 20 different Impressionistic and modern artists; I aimed for about 300-400 images per artist, yielding a total dataset of about 2,700 images (about 500 of which were split off for validation). Although this is a relatively modest dataset size, it ended up doing the job very well. I did have to go through several training runs to get the accuracy above its initial poor score of 0.60, but things turned out well in the end.
At first I was using the resnet34 model, which was rumored to be exceptionally good at classifying paintings. This is one of PyTorch’s pretrained models, and it’s called resnet34 because it has 34 layers in its convolutional neural network. This worked out okay, but generally you want to be achieving higher than 0.60 validation accuracy for a classification model. So I decided to switch to the resnet50 model, which prefers an image size of 224 x 224 pixels and has 50 layers in its CNN. This model performed substantially better, first achieving an accuracy of 0.77 on the initial 1800-image dataset, and then 0.89 on the final 2700-image dataset.
Once you have your data in the artist folders, this is all you need to do to train your model -- just two simple code cells.
# Create the Datablock
dls = DataBlock(
blocks=(ImageBlock, CategoryBlock),
get_items=get_image_files,
splitter=RandomSplitter(valid_pct=0.2, seed=42), # split 20% of the data off for validation
get_y=parent_label,
item_tfms=[Resize(448, method='squish')]
).dataloaders(painting_data_updated, bs=32)
dls.show_batch(max_n=20) # show a sample of 20 images that the model will be trained upon
# Train the resnet50 model
learn = vision_learner(dls, resnet50, metrics=error_rate)
learn.fine_tune(4) # train for 4 epochs
The Production Process
Once I finished training the model and was satisfied with the result, I moved onto the production process. In the previous blog post, I touched on the difficulties I was having with HuggingFace in setting up a space for the model; I managed to resolve these issues a few days ago and get moving. The Ashryver V1 model (and any successive models) are running in a HuggingFace space, which I’ve set up and named ‘erilea-models’ to embody the fictional continent of Erilea. This space behaves somewhat like a GitHub repository, which you can clone down to your computer to add code and add models that can be represented using HuggingFace’s UI. All I had to do with this repository was drop in my pre-trained model in the form of a PKL file, and then call that file to make predictions using a simple notebook. That notebook then launched a Gradio interface (essentially what creates the graphical UI you see on the space itself) that allowed the model to make live predictions.
This way, you don’t have to clone down the entire repository and install a bunch of insane packages to play around with the model. You can just go to the HuggingFace space (which I’ve made public), upload your own images, and have it make predictions. There’s actually even more I could do with this model, like using the Gradio API to place it on one of my own websites and use some custom JavaScript to make it look a bit different. However, the current HuggingFace solution works perfectly fine for this V1 model; I may consider switching to a more advanced API solution for V2.
Next Steps
Speaking of V2, let’s take a final look at my next steps for the Ashryver model. I’d like to improve the model’s reliability on Matisse paintings; right now it continually misclassifies Matisse’s tape drawing The Bees. I’m not sure how to deal with this one, as it isn’t a “painting” in the traditional sense, but users might still want to predict with that image. There have also been some isolated issues with other artists, where incorrect predictions crop up every so often.
For V2, my plan is to find some way to deal with the ridiculous watermarked images or those that contain overlaid text in the training process, as these really seem to be sabotaging the model. I also would like to add a bit more data if possible, maybe for certain artists only, so the model can get a more comprehensive view of what’s going on. I may also add some additional artist categories (although this is optional), and I would definitely like to add a “sister” model that is designed to recognize the artistic era or period of a painting, and use that model to make “backup predictions” of a painting’s era in addition to the artist, in case you give the model a painting that it’s not familiar with. These enhancements should make the Ashryver model much smarter overall as a painting classifier; once I get these improvements done, I should be ready to move onto Unit 3 of the fast.ai Practical Deep Learning course.
Don’t forget to check out the model on HuggingFace, or go to the AI, ML & Web Projects page to play around with the widget. Stay tuned for more updates!